本文整理自 2020 北京网络安全大会(BCS)企业安全运营实践论坛上滴滴安全专家刘潇锋的发言。
刘潇锋,具备多年大型互联网企业反入侵 SDL 运营体系建设经验,从 0 到 1 主导了滴滴的 SDL 平台、智能入侵检测响应平台的建设。同时兼任滴滴账号信息安全负责人。

大家好,我是来自滴滴网络安全部的刘潇锋,很荣幸参加 2020 北京网络安全大会 - 企业安全运营实践论坛。在本次大会期间我被邀请做一个主题报告,我报告的题目是《安全运营之自动编排的探索》。
在本次报告中,我会从三个方面做介绍——

一、安全事件检测与响应,也就是 IDR 流程的运营困境和挑战;
二、安全编排自动化与响应,也就是 SOAR 的概念,以及它能为安全事件检测与响应流程带来哪些改善;
三,我会结合滴滴的实践经验和探索,介绍贴合甲方实际场景的 SOAR 建设思路。
一、基于传统的 SIEM/SOC 的 IDR 运营中主要面临下面几项困难和挑战:
(一)海量异构的日志数据源;
(二)有效的告警会淹没在误报当中;
(三)告警研判推理的挑战;
(四)人员流失给团队带来的挑战;
(五)如何针对事件检测响应去建构知识体系;
(六)如何对事件检测响应工作建立科学的度量和评价体系。
下面我做一下展开介绍:
(一)海量异构的日志数据源,主要有四方面的特点:覆盖广,来源多,量级大,异构性。

1、覆盖广:我们通过各类 sensor 采集的数据,覆盖了办公网和客服网的终端,以及测试网生产网的服务器,还有公有云的虚拟机等等。
2、来源多:包括 HIDS,网络层的 NTA,终端 EDR,还有 VPN 的认证日志,DNS 的解析记录,802.1x 的认证,AD 域控的日志,还有防火墙邮件服务器密罐的日志等等。
3、量级大:我们每天用于安全审计的原始日志达到了 10Tb 及以上的量级。
4、异构性:我们设备采集的日志数据存储在不同的大数据组件中,包括 Hive、ElasticSearch、Kafka 等等,而有些日志是设备通过 Syslog 和 Webhook 的方式打给我们的,这些日志都是异构的。
(二)有效的告警淹没于误报当中,有以下三个原因:

1、样本空间之困:我们通常会通过黑名单的规则来定义异常,因为可以保证较高的准确率,比如一些恶意样本的哈希、黑域名等等。但一旦新的恶意样本不在我们的黑名单库中,我们就无法感知到了。也就是说我们无法感知未知的未知,所以有时需要利用白名单规则,通过定义正常来发现异常。举个例子,某个业务接口,它的参数值如果是整型的,就是正常的,一旦我们接收到了这个参数值是一个字符型的,我们就发现了异常。但由于入侵检测领域正负样本空间是不对称的,我们很难无损地定义正常从而反向发现异常,所以必定导致大量的正常事件混入了异常告警中,产生了误报。
2、统计规则阈值的选取也和误报息息相关:我们通常使用一些统计规则来识别异常,比如说 SSH 账号的爆破异常告警,研发输错了密码也会触发告警,但这个就属于误报,阈值的选取决定了误报的多少,那么在日常运营中统计规则的阈值应该如何设置呢?可能很多时候它并不是基于科学的统计方法,而是安全工程师拍脑袋决定。
3、在甲方日常的安全运营中,团队可能会受 KPI 的影响:宁可错杀一千不可放过一个,也就是说有时候我们为了得到更多的召回,而不得不处理大量误报的工单,所以这也是运营中对于误报率和召回率的取舍问题。
(三)告警研判推理之困,主要有下面四个原因:

1、告警来自于异构数据源是碎片化的:如果我们缺少有效的关联分析能力,就很难从各个孤立的告警中还原出攻击者的一次战术动作,
2、告警研判过程中存在重复低效的二次取证的工作:比如 说有些研判是需要和员工通过邮件或者 IM 方式进行沟通,存在沟通成本,客观上就拖慢了 MTTD 指标;
3、不完备的资产实体库:虽然各个公司大家都有自己的 CMDB、IT 资产管理系统和运维管理系统等等,但是依然存在无法找到研发运维负责人的资产的情况,导致我们的研判被阻塞了。
4、研判过程中还缺乏知识的指引:很多时候研判的动作是凭借技术运营同学的经验,缺少标准的动作指引,导致新人来了无法了解事件应该如何研判,最终研判的效果也是因人而异的。
(四)人员流失给团队带来的挑战:

我们知道网络安全它是一个战线长兵种多的领域,入侵检测也是一样。我们横向看能力栈其实覆盖了 Linux、Windows、移动端、Web、云等等,很难单一技术同学可以 cover 所有的技术栈;纵向看,由于工作年限的不同,职级的不同,导致能力梯度也是分为高中低的,所以如果我们不能固化技术知识,我们就不能缓解由于人员缺位导致的能力的缺失。如果我们不能建立运营流程的标准化,我们也就不能缓解由于能力梯度导致的运营过程中的非标准化的动作。
(五)如何针对事件检测响应去建构知识体系:

因为知识主要分为知识模型、知识交换、知识运用和知识迭代这几方面。
知识模型就是我们 IDR 知识库是基于什么知识模型去组织和建构的?我们知道有 STRIDE 的模型,还有洛克希德马丁公司的 kill Chain 杀链模型,还有这几年比较火的 ATT&CK 模型,还有之前 MITRE 公司的 CAPEC 、CVE 模型等等。
知识交换,指交换威胁情报和 lOC 识别的知识,目前业内比较通用的有像 STIX2.0,还有 TAXll 协议。
知识运用就是指我们建立了知识模型,也通过交换协议获取到外部的威胁情报,那么如何运用知识来指导我们做 lOC 规则的开发,如何做研判策略的设计,以及如何制定事件处置的 SOP 流程等等。
知识迭代主要分为两个方面,一是知识模型自身的迭代,比如说近期 ATT&CK 模型也推出了 Sub-techniques,就是子技术的概念。另一方面就是日常运营的案件如何反馈到知识模型来做迭代。
(六)如何建立科学的度量和评价体系:

我们在事件检测运营中有很多指标,比如围绕资产实体的,有 HIDS 部署的覆盖率,比如终端 EDR 的安装覆盖率,还有跨网络、跨安全域网络边界、南北向流量检测覆盖率等等。还有围绕运营流程的,比如像比较核心的 MTTD/MTTR 指标。还有围绕能力矩阵的,比如 ATT&CK 矩阵的覆盖率。指标的选取,它关系到能否把控安全态势的全局以及能否做好牵引能力的建设,因此选取有效的度量和评价体系,也是存在挑战的。
二、安全编排自动化与响应,也就是 SOAR 的概念,以及它能为安全事件检测与响应流程带来哪些改善
(一)SOAR 的概念介绍。

根据 Gartner 的定义,SOAR 是一系列技术的合集,它能够帮助企业和组织收集安全运营团队监控到的各种信息,也包括各种安全系统产生的告警,并对这些信息进行告警分诊和事件分析。在标准工作流程的指引下,利用人机结合的方式,帮助安全运营人员定义或是做优先级排序,来驱动标准化的事件响应活动。SOAR 工具使得企业和组织能够对事件分析与响应流程进行数字化的定义和描述。
从右图来看,SOAR 分为安全编排自动化,安全事件响应平台,以及威胁情报平台三种技术工具的融合。其中安全事件响应平台和威胁情报平台大家比较熟悉了,安全编排和自动化是一个相对较新的概念。编排是指将事件检测和响应的执行逻辑和流程,通过剧本这种方式来做数字化的定义和存储下来。自动化指的是将一些外部调用封装成自动化的脚本,或者说将第三方可扩展的安全产品,集成到里面做自动的调用,也包括了剧本任务的自动执行。这样讲可能比较抽象,我们更详细地解读一下 SOAR 是如何加速事件检测和响应,以及剧本编排的概念。
(二)SOAR 如何加速事件检测和响应
首先在 IDR 运营流程中,我们接收到一个异常的事件 Event,我们如何通过 SOAR 的思想来处理这个事件,从而提升 IDR 流程的效率?
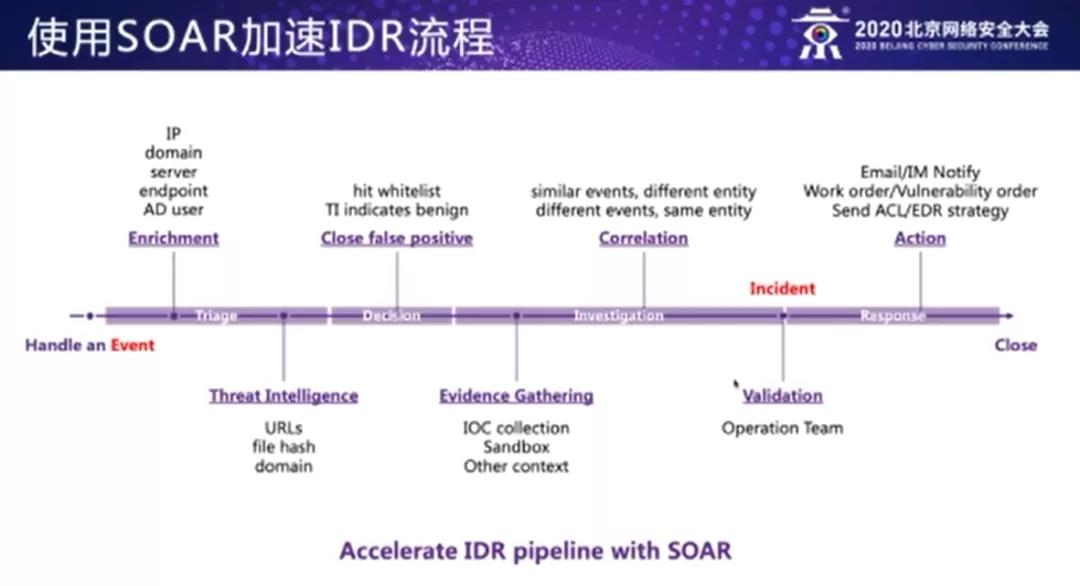
首先是告警分诊。一个原始的告警里边可能只包含了少量的事件信息,我们需要在这个阶段使告警丰富化,也就是 Enrichment 概念——将原始告警中的 IP 服务器,终端 ID 这样的字段,在我们内部的资产库当中查询出详细的信息,并且自动补充到告警信息中。如果包含员工账号,我们也可以从 AD 里边去查询到员工的姓名、部门、职级这些信息补充进来。接下来调用威胁情报平台去初步地匹配原始告警中的比如 Urls、文件或者域名等等,看他是否命中了恶意的情报的样本。
经过了第一阶段的告警分诊,我们可以做初步的决策,比如有些字段命中了白名单库,或者威胁情报显示这是一个非恶意的良性的特征,我们就可以将告警作为误报直接关闭,减少后面人工审计的运营负担。没有作为误报关闭的这些可疑告警,就会进入到下一个阶段——调查取证,在这个阶段我们通过 SOAR 的自动调用能力,可以调用后台的数据,收集更多的 IOC 信息,我们也可以调用沙箱这个能力对可疑文件进行动态的检测,得到检测结果,从而实现证据的自动收集。
接下来我们通过溯源关联分析,实现告警事件的上下文相关联事件的聚合。比如说同一个告警事件,它发生在不同的资产实体上,或者说同一个资产实体,它在一定的时间段内,发生了多类的告警事件,经过前期的告警分诊、误报关闭、调查取证的几个阶段,原始的事件 event 就转化为了一个需要人工验证的 incident 案件。在这个环节安全工程师会根据前面 SOAR 自动补充和取证的信息做出研判,进入到对这个事件的响应的流程。响应阶段也可以利用 SOAR 自动地执行安全处置的动作,包括邮件 IM 通知员工,或创建处置或漏洞工单,或是向防火墙/终端 EDR 下发安全策略(比如封禁)等等。这样我们就通过 SOAR 完成了一次告警事件的检测与响应的流程。
(三)剧本编排的概念
接下来我们看一下剧本编排的概念,看一下如何通过剧本将 IDR 的流程固化下来,这里边我们以钓鱼邮件检测与响应的剧本为例。
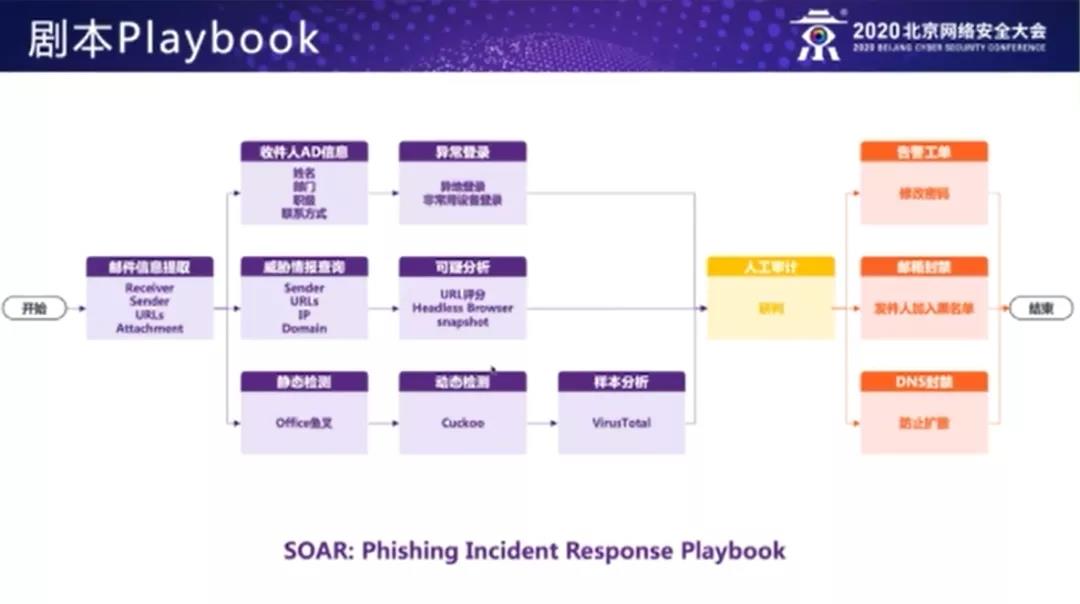
我们在检测钓鱼邮件时,首先是提取邮件的信息,包括发件人、收件人、正文里可点击的 url 链接列表、附件等等。
我们提取出收件人可能是我们公司的员工,我们就可以从 AD 里查询出员工的相关信息,可以自动去邮件服务器的访问日志里面去查看员工近期有没有异常的登录行为,比如说异地登录,或者是使用非常设备登录等等。
对于这个邮件正文里面提取到的 URL 链接,我们首先去威胁情报里查一下有没有命中情报样本。针对 URL/IP/域名,我们也可以拿发件人去威胁情报里做匹配。针对可疑的 URL 链接,我们可以结合像 Whois 信息,像域名的信息,对 URL 进行评分。我们可以使用无头浏览器去对链接做模拟访问,通过自动化的方式来查看动态渲染后的页面里面是否包含诱导用户点击或输入用户名密码的可疑行为,继而将模拟访问得到的页面快照存下来。
我们针对邮件的附件也可以做静态分析,看是否包含 office 鱼叉。我们还可以利用 Cuckoo 这样的动态沙箱对邮件附件里的可执行文件做行为检测。我们还可以利用外部的比如 Virus Total 这样的样本分析平台,来看是否命中恶意样本。
经过信息的自动化收集和分析的动作,我们进入到最后的人工审计环节。这个时候安全工程师会结合前面自动收集的信息去做研判。一旦安全工程师识别出这是一个有效的钓鱼邮件,也会通过剧本的方式去执行后续的这些自动化的动作,包括向员工发送告警工单,要求他修改域账号的密码。我们还可以将发件人的邮箱加入邮件安全网关的发件人黑名单列表里,防止他再给其他员工继续发邮件。我们也可以将恶意的或可疑的钓鱼邮件链接的域名加入到我们 DNS 封禁列表里,来防止进一步的扩散。
即使你在办公网里面收到了这样的邮件,你点击的话,你可能也很难路由到一个正常的地址里,这样我们就针对钓鱼邮件的检测与响应流程,通过这个剧本就固化下来了。
三、结合滴滴的实践经验和探索,介绍贴合甲方实际场景的 SOAR 建设思路。
前面我们介绍了在甲方公司从事 IDR 运营工作的困难和挑战,也介绍了 SOAR 的概念和利用 SOAR 能为 IDR 工作带来哪些改善。接下来我们结合滴滴的一些实践经验和探索,介绍一下贴合甲方实际场景的思路的建设思路。
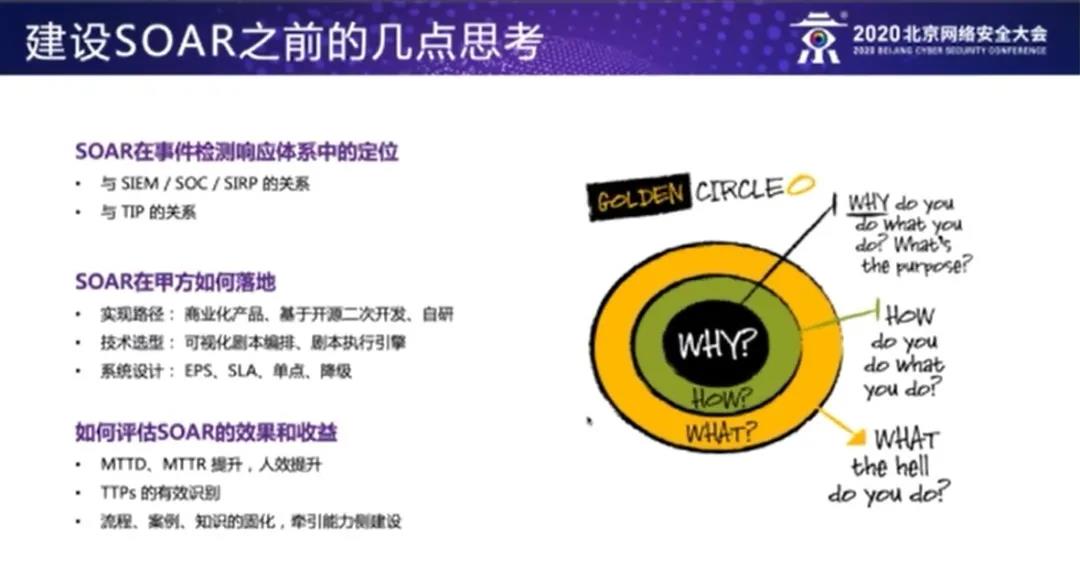
(一)在建设 SOAR 之前,我们需要明确 SOAR在事件检测响应体系中的定位,也就是它与 SIEM/SOC/安全事件响应平台 SIRP 之间的关系,还有它与 TIP 威胁情报平台之间的关系。
我们知道在 SOAR 这个概念出现之前,就已经存在了事件响应平台,SOC 或者威胁情报平台这样的概念,而引入 SOAR,可以将事件检测响应能力得到大幅度的提升,也会促进威胁情报平台和事件响应平台的深度融合。所以说 SOAR 可以理解为是事件响应平台或者是 SOC 的扩展能力。 当然 SOAR 也可以作为一个独立的平台,与 SOC 和 TIP 实现打通。
(二)SOAR 在甲方如何落地,主要考虑三方面:
1、实现路径:
(1)可以采用商业化的产品,近期我们也看到很多国内外知名安全厂商陆续推出了 SOAR 这款产品。
(2)我们也可以基于开源工具做二次开发,比如说剧本编排引擎,它特别类似于一个 Workflow 的工作流引擎,我们可以基于开源的像 Activity 或者是 Airflow 这样的工作流引擎去做二次的开发。
(3)使用自研的方式。
2、技术选型:主要是考虑可视化剧本的编排引擎,还有剧本的执行引擎。
3、系统设计:SOAR 虽然是一个扩展的能力,但是从系统设计的角度来说,一旦我们引入 SOAR,就会将它串联到我们整个的 IDR 流程当中。所以 SOAR 自身的稳定性,还有一些其他的技术指标,比如像 EPS 每秒处理的事件数,SLA,包括一些其他的 benchmark 等等,这些也是我们关注的重点。刚才也提到 SOAR 会串联到 IDR 流程里,所以它有可能会引入或导致一个单点问题,所以我们也会考虑分布式的部署。还有降级,一旦 SOAR 不可用的时候,我们的 SOC 或者事件响应平台能否降级到没有 SOAR 的状态。
(三)如何评估 SOAR 的效果和收益?
1、对 IDR 核心运营指标 MTTD 和 MTTR 的提升,它能让我们技术运营投入更少的人力去做更多的事,提升人效。
2、他能否通过 SOAR 来识别攻击者完整的战术动作,也就是 TTP。
3、通过将剧本的引入,将流程案件知识固化下来,牵引我们能力侧的建设。
(四)结合滴滴的经验和探索,介绍一下 SOAR 的系统设计思想
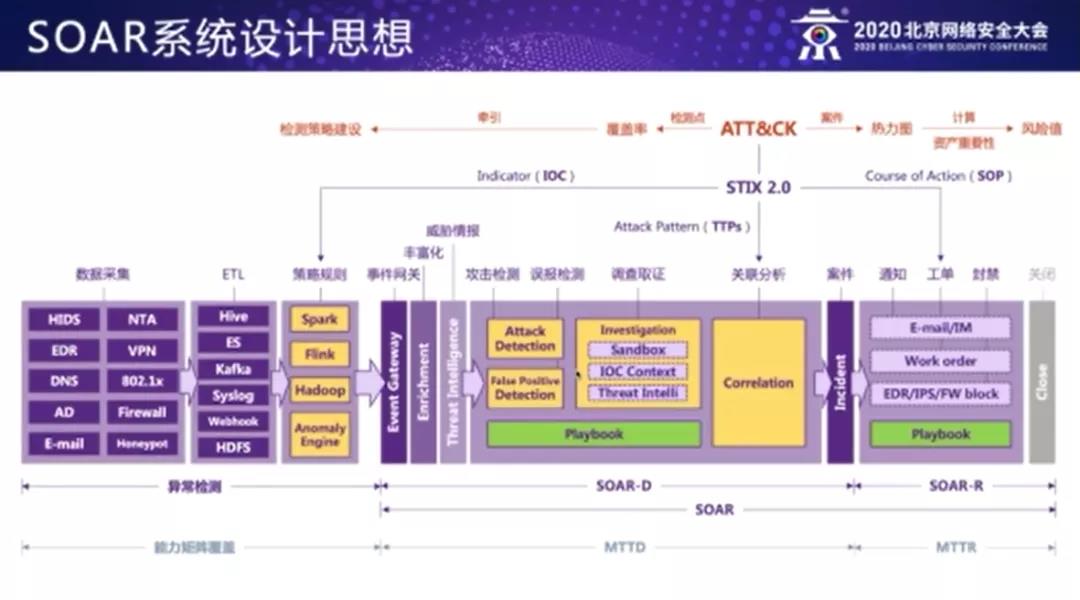
首先我们从各个 sensor 采集到的数据经过 ETL 存储在大数据的组件当中。我们的策略规则是作用在这些大数据的计算引擎上,像 Spark,Hadoop,还有 Flink 这样实时的引擎,也包括我们自研的异常检测的引擎,最终产生的异常告警事件会打到我们的 event gateway 通用事件网关上。这一阶段被我们称为异常检测阶段。
事件网关主要做两个事:一,做标准化,将这些异构的数据源产生的各种类型的告警里的字段格式和数据类型做标准化,以便后面我们在做 SOAR 编排的时候降低成本。二,在这个环节我们会做 index,把原始的告警事件索引到数据库里,以便我们后面做关联分析,或者我们可以回溯的时候去实时地查询历史的告警事件数据。
经过事件网关以后,我们紧接着做两个事情,一个是做 Enrichment 丰富化,第二个是做威胁情报。我们在丰富化这个阶段会补齐像服务器地址、员工信息、终端信息和调研我们内部的核心的资产库,将告警信息做丰富化。 第二就是我们会初步匹配告警字段里边比如像域名,像文件哈希,去我们本地的威胁情报库里面做匹配。
接下来就进入到我们的核心检测阶段 SOAR 编排环节,在这个环节我们将各种检测能力抽象成为各种检测引擎,比如像攻击检测引擎、误报检测引擎、调查取证引擎和关联分析引擎等等。
攻击检测引擎是做什么?主要是根据告警事件里的一些字段去我们本地的黑名单库列表里做匹配,一旦确认命中我们的黑名单,就可以不需要做后面一些列复杂的调查取证和关联分析工作,可以直接交给人工来做研判,甚至对它可以绕过人工来做自动化响应。
误报检测是根据字段里边的一些特征,以及我们之前配置的白名单规则,命中了白名单,这个事件我们可以把它自动关闭掉,以减少后面调查取证的负担。
调查取证我们是将一些通用的外部接口和能力封装成一些函数或者脚本,来做自动化的调用。而这些封装的能力之间,我们也是以一个子剧本的方式来进行编排,它可以根据剧本流程的配置来做自动化的执行和调用。
关联分析引擎也是基于我们配置好的一些关联分析的规则,来针对这一个告警事件的上下文,或者一段时间内它同资产的一些其他告警事件来做关联和聚合,上报给人工去做研判。
这些不同的检测引擎之间,我们也是通过剧本的方式把它进行一个整体的编排。有些我们可以先经过攻击检测引擎,误报检测引擎,再做调查取证和关联分析;而有一些告警类型,我们通过剧本的编排,它就不需要去做攻击检测了,比如他通过误报检测就可以直接到调查取证检测。这些其实都是通过剧本来实现一个动态编排。
经过这个阶段的检测,我们的原始事件就形成了一个具体的需要人工验证的案件,也就是 incident。从原始的事件到案件,这个阶段我们称它为是检测阶段的 SOAR 编排。这阶段经过人工的验证,如果是一个有效的案件需要经过处置的话,它就会进入到后续的自动处置的流程里面。而这一阶段我们也是通过剧本的方式,将各种处置能力封装来自动编排上。这里边包括像通过邮件和 IM 消息的方式来通知用户,也包括我们调用工单系统,还有就是我们调用 EDR/IPS/防火墙的一些封禁策略等等,把它封装成自动的脚本,通过剧本的方式做编排,做自动的调用。
从案件到事件的最终响应结束这一阶段,我们称它为是响应阶段的 SOAR 编排。从事件网关到整个案件结束,这个阶段就是我们核心的整体的 SOAR 编排流程。
前面讲过,我们需要用知识来指导我们去做入侵检测与相应的建设,我们在做 SOAR 系统设计的时候,是如何把知识体系来融合到系统设计里的呢?
在上文提到的情报交互里有一个 STIX2.0 协议,STIX2.0 有很多个构件,其中有几个构件其实是可以指导我们去做异常检测规则的开发,以及 SOAR 编排里的关联分析和处置动作的。比如像 indicator,就可以指导我们去做异常检测阶段的 IOC 规则开发;还有 Attack Pattern,描述的其实就是 TTP,可以指导我们在 SOAR 检测阶段去做关联分析规则;还有 course of action 构件,它是指导我们在做响应处置阶段的 SOP 的流程。
我们前面也提到了 ATT&CK 模型,其实 ATT&CK 模型和 STIX2.0 之间是有映射关系的,我们可以将我们的异常检测规则映射到 ATT&CK 模型上,主要是做两个事,第一个就是我们根据现有的检测点,可以总体来看我们对 ATT&CK 的覆盖率,这样它能牵引我们去做能力侧的建设,也就是检测策略建设。当我们发现缺少哪一部分的检测能力,我们就可以去部署新的 sensor,开发新的 IOC 规则。
我们也可以结合 ATT&CK 模型去和我们的真实的日常运营中的案件做结合,去查看我们 ATT&CK 热力图,去从整体安全态势上看我们哪些场景是经常会被攻击的。我们也可以结合资产的重要性、等级和实际发生的案件,通过一个公式来计算出我们整体的风险值。
前面我们提到了指标这个概念,整个 SOAR 流程和指标体系也是紧密结合的,包括我们在异常检测阶段有能力矩阵的覆盖率这样的指标,还有我们在检测阶段的 SOAR 编排决定了我们的 MTTD(平均检测时间)的指标,以及在响应阶段 SOAR 关联了我们的 MTTR(平均响应时间)指标。
这样我们就围绕着 SOAR 的系统设计,将 IDR 事件检测与响应流程、SOAR 的自动编排、知识体系和指标体系,都融合在了我们整个的 SOAR 的系统设计思想里。
好,我的分享就到这里,谢谢大家。
转载于微信公众号【君哥的体历】
声明:本文来自微信公众号 - 君哥的体历,版权归作者所有。文章内容仅代表作者独立观点,不代表本人立场,转载目的在于传递更多信息。如有侵权,请联系 [email protected]。