1 摘要
本文介绍了为什么在一个好的公有云或私有云中必须要有一个编排系统来支持云上自动化,以及实现这个编排系统的困难和各家的努力。同时提供了一套实现编排系统的原型,它包括了理论分析及主体插件框架,还给出一些细节控制的建议。希望有助于大家对 “资源编排&应用编排” 概念有更深的了解,也希望以开放的心态与大家一起努力,使得云真的像水电一样自然和普及。
2 为什么需要云上自动化
IT 领域的自动化要求无需多言,每个程序员都知道这是必须品。自动化脚本,自动化测试,自动化部署等等,都是为了程序及围绕此程序的各类程序员跑的更加欢快。那么在云上我们是否还需要自动化?简单而言,初次使用无需考虑;深度用户需要云上自动化。具体体现在:
2.1 重复性的执行动作
在云上验证应用上线的工作中,有很多的事情是需要重复操作的。比如环境的销毁和重建;或者扩容的场景下,重复地完成多个新实例的配置动作。一旦此类操作的频率变高,比如一天一次或者一天多次的时候,你一定会觉得繁琐,并且开始尝试如何使得整个流程变的自动化,从而保证每一次执行是可重复的。也许你会写些 Shell 或者 Python 脚本,或者你主动调用云提供商的 API,甚至借助某些工具如 Chef,Puppet 来完成这个目的。
重复是催生自动化的首要条件。
2.2 节约时间
在云上使用服务,有些操作是非常耗时的,比如创建数据库,创建 VM,都需等待分钟级别的时间。一旦需要串行的创建多个耗时任务,就需要用户持续等待一段时间。而此时如果可以将整个流程自动化,则可以释放人为的等待过程,使程序员去完成其他更有价值的任务。
云上的流程自动化后,执行动作的总体耗时并不会减少,只是这段等待时间可以被转移,比如放在深夜执行。也正是这个原因(耗时没有减少,只是转移了),所以自动化后时间的节省,还是要以重复性为前途的。假如只是一次性的操作,那么 “自动化节约的时间” vs “完成自动化的时间” 一般都是不划算的。
2.3 基础环境的复制
这里的基础环境是指 Infrastructure,是指应用跑在云上所需要的所有云服务的集合。例如一个典型 Web 网站的 3 层架构,前端 + 后台 + 数据库。在云上的某个区(例如华北区)域搭建好一套完整的系统后,遇到需要在华南区甚至另一个云提供商的云上,重新搭建一样的环境的时候,就会有系统复制的需求。是靠程序员手动一个一个组件的安装?还是自动化的一键重复部署?在有后者能力的情况下,当然后者是首选。
现在很多云厂商都推行一个叫做 Infrastructure As Code 的概念,使用机器可以理解的配置文件,来代替人工交互式的配置动作。并且这种配置文件可以通过版本管理系统像代码一样进行版本管理。这样对于企业的好处主要体现有 3 个:减小成本、提高效率、降低风险。
减小成本很好理解,如上提到的,自动化可以将人力转移到其他任务上,提高程序员的产出。而效率的提升主要体现在通过自动化的配置可以将环境安装的实施过程缩短,如果有多个组件或者团队交互的话,提升效率就更明显了。同时自动化可以消除人为的错误,可重复的执行特性也提升实施过程的可靠性。
2.4 自助式服务
云上服务,如果做得好,应该是自助式的,就像自来水和电一样,即开即用,按需付费。只有这样子才可以支持任意的自动化按需供给、按需扩容,也才是云本身所具备的含义。
所以这一条理由其实是对云提供商提出的要求,你的云平台要能够支持用户自助式的按需使用各种云服务,并提供相应的使用计量信息(账单)和使用报告。只有当平台的后端实现流程是全自动化的,才能做到给用户的体验是完全自助式的。这跟淘宝商家的 “有货随便拍” 一个道理,否则没到下单前都得跟店家沟通,无法做到按需自助式使用。
2.5 小结:自动化的成本
任何需要自动化的东西,前提就是你需要重复的执行,只有当自动化的收益大于重复的成本,才会有自动化的需求出现。假如任务只是一次性的,那就不存在自动化的需求。相反我们相信从收益方面考虑,精心人工操作一遍会比将流程自动化更为划算。
好比有时候路上遇到口渴并不会想安装一套自来水,还不如直接买一瓶矿泉水来的实在,而在家里,则需要安装一套自来水系统,因为你每天都需要使用水。
云上的自动化提供了一种可靠性,它使得云资源,云服务的每一次创建的行为都是一致的,任何用户,任何组织的执行都是可重复的;同时也消除了由于人为操作可能的失误所带来的问题,是云上深度用户的必需品。
3 云上自动化演进
3.1 自动化面临的困难
(1)云服务的种类丰富多样,导致想要完成全面的自动化并非易事。一个典型的云平台会提供了 ECS(虚机),EVS(硬盘),VPC(网络),RDS(数据库),ELB(负载均衡)等等一系列数都数不清的服务。有一个新的术语叫做 AWS fatigued,就是说 AWS 每年都会上线各种新服务&新特性,使得用户对新上线的服务&特性都感到了 “AWS 疲乏”,疲于使用。
(2)云服务间的创建存在复杂的依赖关系。最典型的例子就是,当创建 EIP 的时候,需绑定 VM,而创建 CM 的时候,又需要先创建 Subnet,建 Subnet 的前提就是需要先有 VPC。层层的依赖,以及交叉依赖,都为开发者在企图自动化的道路设置了拦路虎,使得完成自动化的成本大大提高。根据前面提到的成本大于重复性收益的时候,自动化就会被放弃。
(3)云上资源的使用方式与传统方式不同。用户从资源的完全拥有者变成资源的使用者,后台权限的降低,导致你无法掌控一切,使得不那么方便的定位资源初始化失败原因(也许云平台本身的 Bug 导致)。有时候不得不联系云提供商求助了解失败原因。另外在使用流程上也会稍有改变,原来你的软件包一次拷贝就到了验证环境,而在云上,也许你需要中转跳板才能达到目的。这些都加剧了自动化的实施困难。
3.2 自动化的尝试
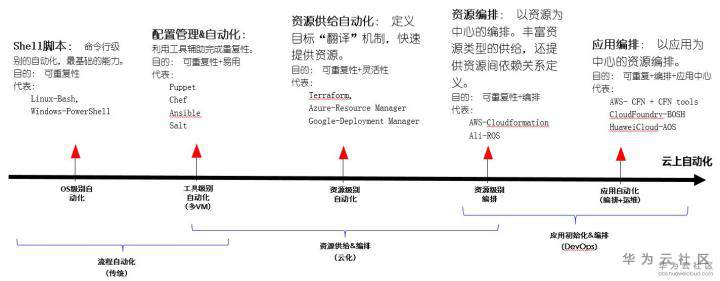
这里直接给一个图来总结了云上自动化的尝试历程,可以更加直观的了解这一领域的发展情况。不过在资源供给自动化和资源编排上其实边界也没有那么的明显,可以看到主要的差异是在灵活的语法上。在已有的自动化模板里面逐步增加一些灵活的语法,基本可以达到灵活编排的目的。
4 终极的自动化体系 - 编排
自动化是指一个任务流程中不需要人为的干预,而编排则是指多个任务流程可以提前规划,任务间可以互相配合,并行或者串行的执行。可以从最直接的定义上看到,只有做到任意的自动化流程控制才能称之为编排,是一个自动化的升级版。由此可见,如果某云厂商的一个编排系统,连一些基础的自动化流程都无法满足,那么它就不是一个好的编排系统。
4.1 云上的编排标杆
提到云上的编排系统,就不得不提老大哥 AWS 的 Cloudformation 了,基本上它已经是 AWS 云生态的一个标准,支撑应用市场以及服务目录完成任意 IT 软件和 IT 基础设施的初始化流程。
它的主要原理就是用户提供创建对象的各种属性,然后 CFN 协助完成对象的创建。例如初始化 EC2,就是相当于创建 VM 虚拟机。那么用户就得提供属性:主机名,用什么镜像,硬盘多大,用什么网络,主机规格,安全组等。有了这些属性,CFN 就可以确定如何调用 EC2 的 API 来创建 VM 了。
它之所以能力很强是因为它除了提供执行顺序的控制能力以外,在语法层面还提供了很多的内置函数,用户可以通过函数来引用变量,拼接变量值,控制执行细节。超丰富的编排对象,使得使用 CFN 基本可以满足任意 AWS 资源的自动化创建。
4.2 云上编排系统对比
这里分析三家典型的提供编排能力的云厂商能力分析表,不对之处也请联系纠正。(亚马逊 CFN、阿里 ROS、华为 AOS)
√表示 “强/做得好”,O 表示 “一般/待增强”,X 表示 “没有此特性”。
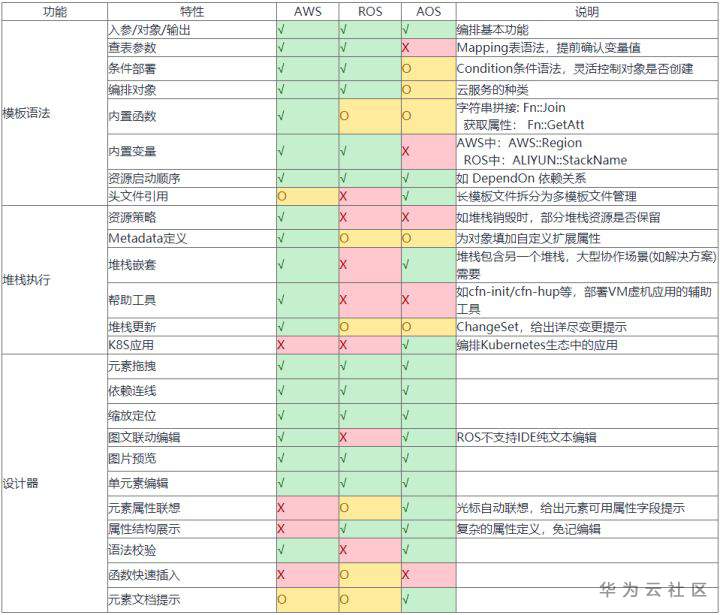
注:OpenStack 的 Heat 编排能力类似 AWS,但是无图形化设计器,这里就不列举了。
4.3 编排系统的不足
当前的编排系统都需要一个描述文件,来描述用户希望的执行流程。一般都会把这个描述文件称之为 “模板”。通过模板来控制执行逻辑,这并不是一个问题,因为你能看到的业界编排系统都有自己的 “模板” 语法规则。问题在于,从无到有的写作一个新的模板,会比较困难,需要使用者学习一定的门槛,大家的第一感觉总是像在学习一门新的编程语言。
这个是由编排的目标对象的复杂度决定的:创建一个 RDS 数据库,就是会比单独创建一台 VM,需要有更多的控制参数。于是一种新的模板语法,相当于一种新的编程语言。写过代码的你肯定知道,想要快速的编码,当然需要合适的 IDE 支撑。也正因此,一些有实力的编排系统就会推出相应的图形化设计器,其定位就是配套的模板写作 IDE。
比如 AWS,阿里和华为都提供了在线的模板编辑 IDE。设计器好坏的评价标准就是能否支撑方便的写作模板。
5 如何实现云上编排系统
一个编排系统的核心就是一个工作流引擎,负责分析各个步骤间的依赖关系,并按照 DAG(有向无环图)模型来控制这些流程的执行顺序。而云上的编排,更加的具化,就是按依赖顺序创建各个云服务。
算法层面,我们可以称每个云服务为元素。创建各种云服务的过程,就是按顺序创建各个元素的过程。
5.1 有向无环图 DAG
有向无环图(Directed Acyclic Graph, DAG), 是有向图的一种,字面意思的理解就是图中没有环。常常被用来表示事件之间的依赖关系,用于管理任务之间的调度。
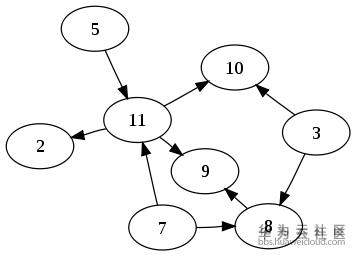
图:一个有向无环图的例子
其中所有节点的拓扑排序是有向无环图中经常需要使用到的算法,我们的系统原型也是按照此理论基础进行实现的。就是把所有元素按照 DAG 依赖关系确定好谁先谁后的顺序,具体算法大家可以在网上或者资料中搜索获得,这里就不细介绍了。排好序后,接下里的实现就是先完成底层的元素,再完成上层元素,直到所有元素都初始化完毕。以上就是我们的编排系统模型的理论参照。
5.2 编排系统原型
在这里我们假设有一个系统的初始化流程如下:
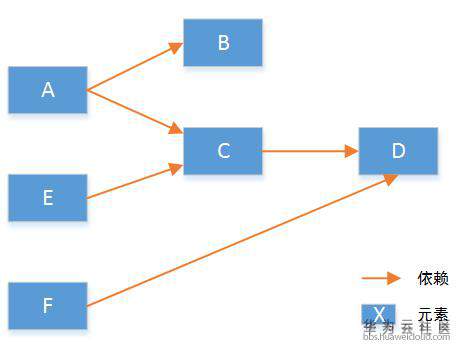
要实现所有元素按照设定好的顺序创建,我们遵从两个要点:(1)默认并行执行。(2)无依赖的先执行。具体算法实现上,我们首先将元素启动顺序分解为有向图,并遍历计算得到每个节点的依赖数。如下:
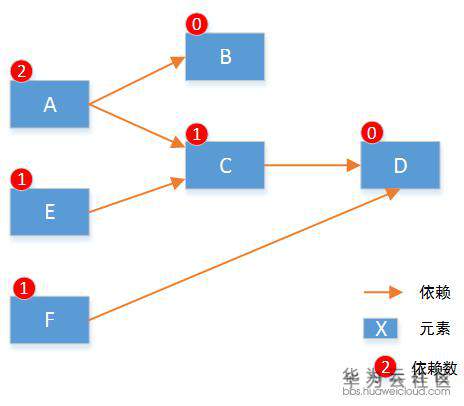
本次可以执行的元素就是 C 和 F,因为它们的依赖数为 0。在这两个元素执行完后,将依赖他们的元素的依赖数减一,重新得到所有节点依赖数:
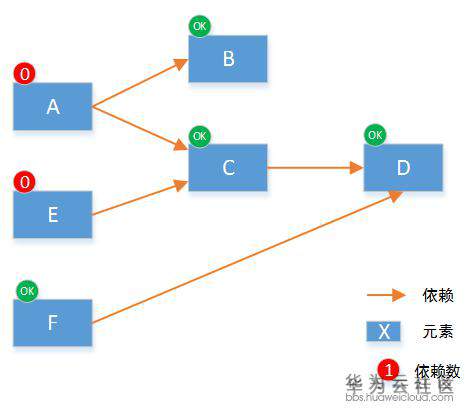
按照上述的逻辑递归执行,直到所有的元素都被执行完,整个工作流就完成了。它保证整个流程是按顺序用时最短的。从工作流实现原理可知,编排的能力强弱并不强调流程控制,而是编排元素,及编排语法的丰富程度。好的编排系统,可以快速的完成新元素的驱动开发,从而提供新服务的编排能力。
5.3 元素间信息传递
如果每个元素初始化,都得记录着其他元素的信息,这种在实现上元素间就很耦合。为了保持每个元素在执行时候的独立性(即当前元素在初始化时,不用去了解其他元素的信息)。主体框架需要保持一个全局信息,然后在初始化一个元素的时候,把这个元素需要的信息告诉它就行。它自己完全不知道还有哪些其他元素,反正它自己需要的信息都有了。
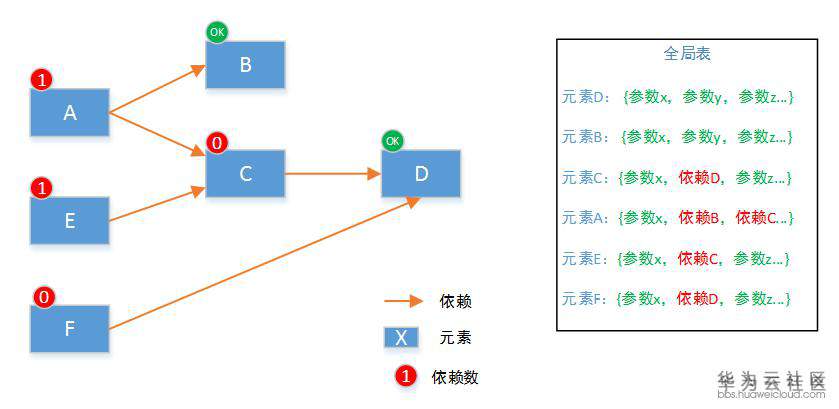
这里举例说明,调度框架维护一个全局信息,记录每个元素需要哪些参数才能初始化。上图绿色的需要用户提供,红色的则在被依赖对象创建后自动获得。比如创建 VM 需要 VPC 的 ID,那么在 VPC 创建后,VPC 的 ID 就知道了,这个字段不用用户提供。
所以在元素 D 初始化完成后,元素 C 就可以开始初始化了。这个时候,所有创建 C 的参数,都应该是确认的值。在调用 C 服务的初始化 API 的时候,不缺任何信息。这样在实现 C 的创建 API 和销毁 API,就非常独立,只与 C 服务本身打交道。
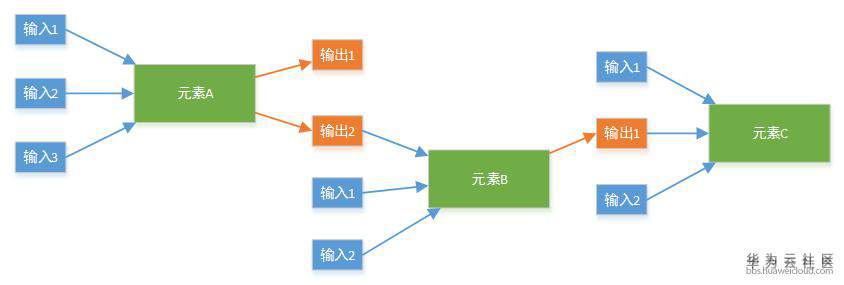
如上图,在开发新服务的时候,只需要了解新服务自身就可以了,所有想要的信息(可以直接要求用户提供,或者通过依赖获得),都会通过框架管理和传递。
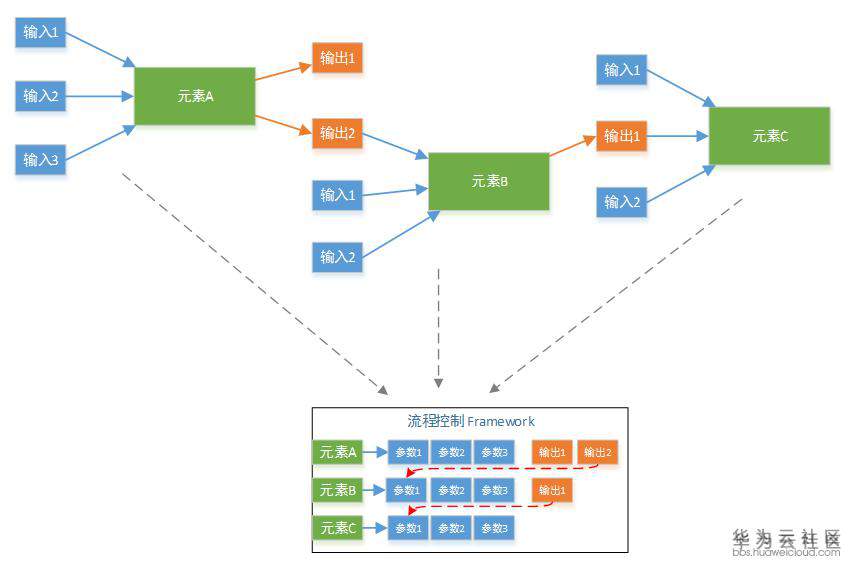
这就是我们的插件化框架,这个框架使得新增一种服务非常容易。因为服务的驱动开发是完全独立的。
5.4 插件设计
5.4.1 元素的生命周期
每一种云服务对象,在编排系统看来都是一个元素。新增一种元素的编排,就需要该元素提供增删改查等基础执行能力。编排系统的插件管理框架会根据用户执行动作,比如创建 or 销毁,来调用元素对应的 API。
有了上一节的元素执行流程框架后,新增一个编排对象,只需要完成该元素的各种行为驱动就可以。例如:只要有创建和销毁 VM 的方法(API),那么就可以在编排元素里面增加一个 EC2 服务,就可以在模板里面增加这种元素的编排了。调度框架只是把它当做一个普通元素来对待。
5.4.2 用户自定义插件
基于插件框架每个元素驱动独立的优势,同时考虑到 Kubernetes 中的 Resource 对象也有自定义扩展特性(custom resource definition),可以设计一种元素插件支持用户定义自己的 K8S 编排对象的能力。即把用户提供的 “信息” 原封不动的传递给底层 API。由底层系统去解释用户的 “信息”。编排系统退化为只负责流程控制 + 信息传递通道。
5.4.3 操作的等待&进度
之前提过,有些云服务的操作非常耗时,如果不能提供整体进度的直观反馈,用户体验就会非常的差,以为整个执行流程挂死。所以在元素驱动的编写时,必须考虑进度和等待反馈,让编排框架能感知执行进度。使得用户可以知道当前在执行哪个元素,该元素的执行进度如何。从而确保整体的编排流程能够给用户最直接和友好的反映。
5.5 TOSCA 模型
有了调度框架&插件框架,剩下的就是配置文件的语法了,目前主要的可借鉴语法就是 AWS 的 Cloudformation 和 TOSCA 语法。其中 AWS-CFN 是以资源初始化为中心的,而 TOSCA 的定义为 TOSCA is a specification that aims to standardize how we describe software applications and everything that is required for them to run in the “cloud”,可见 TOSCA 是更加偏向于面向 App 的。鉴于容器技术的流行,越来越多的应用以独立容器出现,不再强调需要传统的 VM。我们觉得模板语法使用 TOSCA 是个不错的选择。
实际上,在自动化的过程中,你会发现:模板的语法并不是关键点。只要能自动化,模板写出来都不会相差太大,所以关键还是看自动化能力。这个就好比编程语言的选择,Java 和 Go,写二叉树遍历不会在意是用 for 还是用 while。各种编程语言的主要区别在内置函数/库上,所以在模板的语法上提供丰富的自动化便利性才是目的。这一点需要向 AWS 学习,它提供了很多的内置函数。
6 总结
在云上,自动化其实是刚需,只有完成了自动化这个基座,才能构建出完整的云生态。而编排作为一种高级自动化能力,需要负起推动云生态走向完整的重任。是检验一个云厂商实力的硬通货。
华为 PaaS 团队在云上,特别是 PaaS 云上的自动化&编排领域,有多年的探索和积累。在此希望能与业界一起分享并推动云上编排领域的发展,使得在云的使用过程中能带来更好的用户体验,让云上自动化能真正如云这个趋势一样无处不在。
如果有好的想法&建议,也可以跟我们交流。
转载于 (https://bbs.huaweicloud.com/forum/thread-67791-1-1.html)
本文作者:华为 PaaS 架构师 唐老师
声明:本文来自华为云,版权归作者所有。文章内容仅代表作者独立观点,不代表本人立场,转载目的在于传递更多信息。如有侵权,请联系 [email protected]。